

University of Wisconsin-Madison
Related Material: paper, presentation, coding sample
The emerge of the idea "Panorama" has to be dated back to early 20 A.D. and was a means of generating an 'panoptic' view of a vista [1]. Nowadays, with the help of advanced technology, people are able to create desired panorama by simply rotating their cell phones and clicking the shot button. The process of synthesizing panorama is relatively straight forward. First step is to take successive photos from the same optical center and next step is finding the alignment between each image and warping accordingly, and final step is interpolating the warped image and applied certain blending to remove the visible seams. However, the problem with creating panoramas using above approach is that people are required to physically appear at the place where they take the images, which means that if people want to take a panorama of Time Square in New York, they have to fly over New York to do so.
Compared to sequence of images, although some segments within videos have relatively low image quality and also moving object, they are still shot from the same optical center and cover a wide field-of-view. Lui et al. suggests an approach that synthesizing panoramas by identifying proper segments within videos as panorama source [2]. They convert the problem into a optimization problem, and set up three constraints in order to evaluate the video segments. Lui ei al. indicate that in order to be a appropriate panorama source, a video segment should cover a wide field-of-view based on the definition of panorama imagery, be "mosaicable" and the frames should have high image quality
We measure the visual quality or we call image quality of a single frame based on two terms, one is incorrectness of the motion model $\mathit{E_{vm}(S_i)}$ and the source image visual quality $\mathit{E_{vv}(S_i)}$. Then by setting up the visual quality distortion $\mathit{E_v(S_i)}$, we can obtain the visual quality measure.
By default, we set both weights $\alpha_v$ and $\alpha_m$ to be 1.0.
Source Image Visual Quality: The source image visual quality $\mathit{E_{vv}(S_i)}$ is defined as how blurry and blocky the image is.
We use the idea of Tong et al.'s method of measuring blurring artifacts by using Haar Wavelet Transform [3].
The blockiness is measured by using the method of Wang et al. which estimates the average difference across block boundaries modulated by image activities [4].


After obtain the blockiness and blurriness from all the frames within a given video segment, we calculate the visual distortion for this segment as follows:
where $\mathit{q_{bk}(I_k)}$ is the measurement of blockiness of given frame, and $\mathit{q_{br}(I_k)}$ is the measurement of blurriness. Weight $\gamma$ is set to 0.45.
Incorrectness of Motion Model: In order to achieve the "mosaicablity", we use a homography to model the motion between frames. By matching SIFT feature points, we are able to locate significant points between frames and thus obtain the homography. In practice, getting a high quality panorama from video requires the inter-frame motion is closed to its homography and few casual videos can achieve that. Therefore, we measure the error using the real motion vector from SIFT feature points and the predicted value by homography between two successive frames.
We first for each adjacent frame $\mathit{I_k}$ and $\mathit{I_{k + 1}}$ find its matching SIFT feature pairs, and calculate homography using RANSAC based on these feature pairs. The notation $\mathit{mv(p_{j,k})}$ is the motion vector of $\mathit{j^{th}}$ SIFT feature point of frame $\mathit{I_k}$ and $\mathit{mv_h(p_{j,k})}$ is the predicted motion vector by homography at $\mathit{j^{th}}$ feature point. Then the error of $\mathit{j^{th}}$ feature point is taking the L1 norm of these two terms. Then we average the errors of all feature pair in each frame and obtain the incorrectness of motion model by summing up all the average.
The extent of scene $\varepsilon(\mathit{S_i})$ is defined as the scene covered by the video segment. Although it could be good if we maximizing the covering area to obtain a larger field of view, larger field of view often means more distortion. Hence, we want to choose the reference frame where maintains a decent field of view and the distortion is minimum, in other words, we want the minimum area covered by segment $\mathit{S_i}$
In order to find the optimal reference frame, we want to search for all possible combination of panorama alignment as follows:
In Lui et al. paper, they used generic polygon clipping for finding the minimum area covered, but we used another approach. Although the accuracy declines, the complexity reduces in decent amount, we choose to find the distance between the center of reference frame and that of all other frames as follows:
Where $\mathit{n}$ is the number of frames within the segment, $\mathit{C_r}$ is the center pixel of the reference frame and $\mathit{C_f}$ is the center pixel in a given frame.
The results are obtained by using the preprocessed video segments which we manually select shots from certain videos and each segment is around 130 frames. First two panoramas are good results and the last one is a failure. (Lower score means better)



Lui et al. preprocess the given video by applying histogram based method for shot boundary detection and
shot boundary is detected whenever the histogram intersection between two adjacent frames is below a threshold.
However, we detect scene boundary by using the visual quality distortion.The idea is that in order to calculate the homography between two adjacent frames, we should have at least 4 SIFT matching pairs.
According to our experiments, the video segments we have do not always have enough pairs to calculate homography when two frames are at scene boundary and even when they have enough pairs to calculate the visual quality error tend to be high.
Thus, we cut the whole video into 20 frames segments, then compute visual quality error for each segments and by setting the visual quality error to infinity when encounter scene transition segment and dropping that segment
we are able to append all adjacent segments to obtain a optimal segement for panorama stiching.
We define the types of videos that we might encounter while fetching as follows:
1. A scene that is not capable of synthesizing panorama (bad scene) followed by a scene that is proper source for panorama (good scene) or a good scene followed by a bad scene, in both cases we want to only obtain one panorama from the good scene:
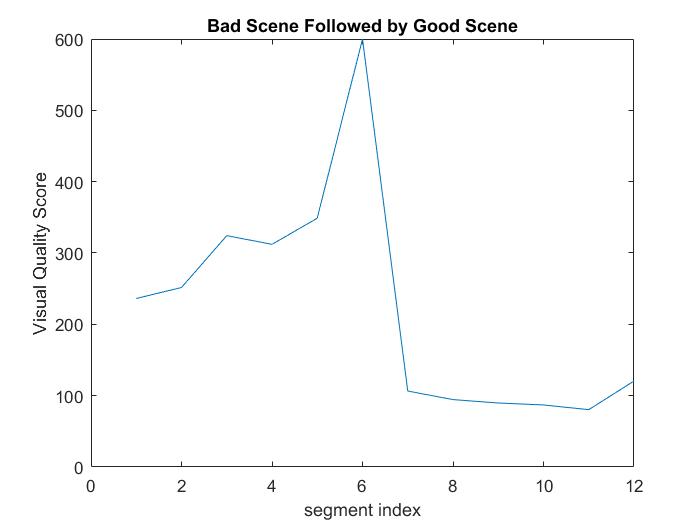
Above figure shows that the overrall visual quality error for bad scene segments are high (over 250) and we have this sudden increase in the error at segment 6, thus we can say segment 6 has a high possibility of containing a scene transition. And we want drop all the segments before segment 7 due to high error and synthesize panorama use only segment 7 to 12
2. A good scene followed a good scene followed. In this situation, we want to get two panoramas :
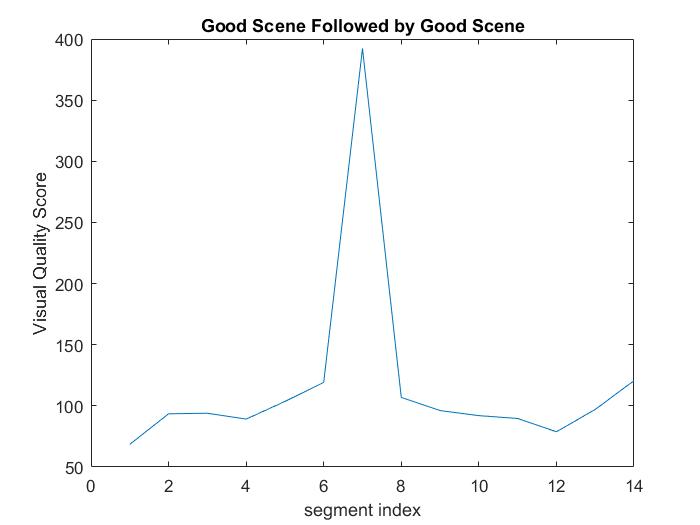
It can be observed that before and after segment 7 there are two smooth segments series and a sudden increase in visual quality error at segment 7. In this case, we want to drop segment 7 and synthesize two panoramas from segment 1 to 5 and segment 7 to the rest segments.
3. A bad scene followed by a bad scene. We want to drop both scenes, and we can expect the overrall visual quality errors are relatively high across all the segments.
[1] https://en.wikipedia.org/wiki/Panorama.
[2] F. Lui, Y.-H. Hu, and M. J. Gleicher, Discovering panoramas in web videos, In ACM Multimedia, pages 329-338, 2008.
[3] H. Tong, M. Li, H.-J. Zhang, and C. Zhang. No-reference quality assessment for jpeg2000 compressed images. In IEEE ICIP, pages 981-984, 2000.
[4] Z. Wang, H. Sheikh, and A. Bovik. No-reference perceptual quality assessment of jpeg compressed images. In IEEE ICIP, pages Vol I: 477-480, 2002.